6 Autonomous AI Agents Trade Stocks for ~$0.87/Day
I built two AIs argue about stocks before letting them spend my money

A Bloomberg Terminal costs about 24k dollers per year. I built a robust system with 6+ AI agents that autonomously research, debate, and trade Indian stocks. Full day of operation: $0.87.
483 debates. 148+ trades. 370k LLM tokens. Under a dollar.
I called it Sudo Trade - kinda like super admin access to the trading with AI and trying to do money maxing. Also thought of naming it vibe-trading or git-rich but both already exist.
sudo-trade is roughly ~7,000 lines of Python. Just a bunch of APIs + asyncio, an event bus, and a lots of LLMs that disagree with each other for a living.
The whole thing started because I wanted to check: If I can utilise my dev skills with most sophisticated AI models to build something that actually trades intelligently? Not a plain simple wrapper that fires market orders when RSI crosses 30. Something with real decision-making. Something that "thinks" before it spends/executes trades.
*think here means recursive API calls to multiple LLMs
How It Was Built
I pair-programmed + vibe coded almost all of it with Claude Code and Codex. Where I was swaping with multiple models like Gemini 3.1 Pro for architecture then Claude Opus 4.6 1M for coding and Codex 5.3 EH for code review. I'd describe what I wanted, we'd argue about the architecture, it would write the code, I'd review with codex, we'd iterate a bunch of times. Finally pulled this in about a week.
But the wild part: Claude Code also runs the trading engine - Master agent. The system ships with an MCP server (Model Context Protocol) - that lets Claude orchestrate everything conversationally. I open my terminal, say "start the engine, screen RELIANCE TCS INFY, debate the top picks, approve the strong buys" - and it does. No complex things. Just navigating to it.
The MCP server is stateless - 8 tools, 7 resources, 4 workflow prompts. It's a thin translation layer between Claude and the engine's HTTP API. The engine doesn't know it's being driven by an AI. Claude doesn't know it's talking to a trading system. They just speak HTTP and MCP in between.
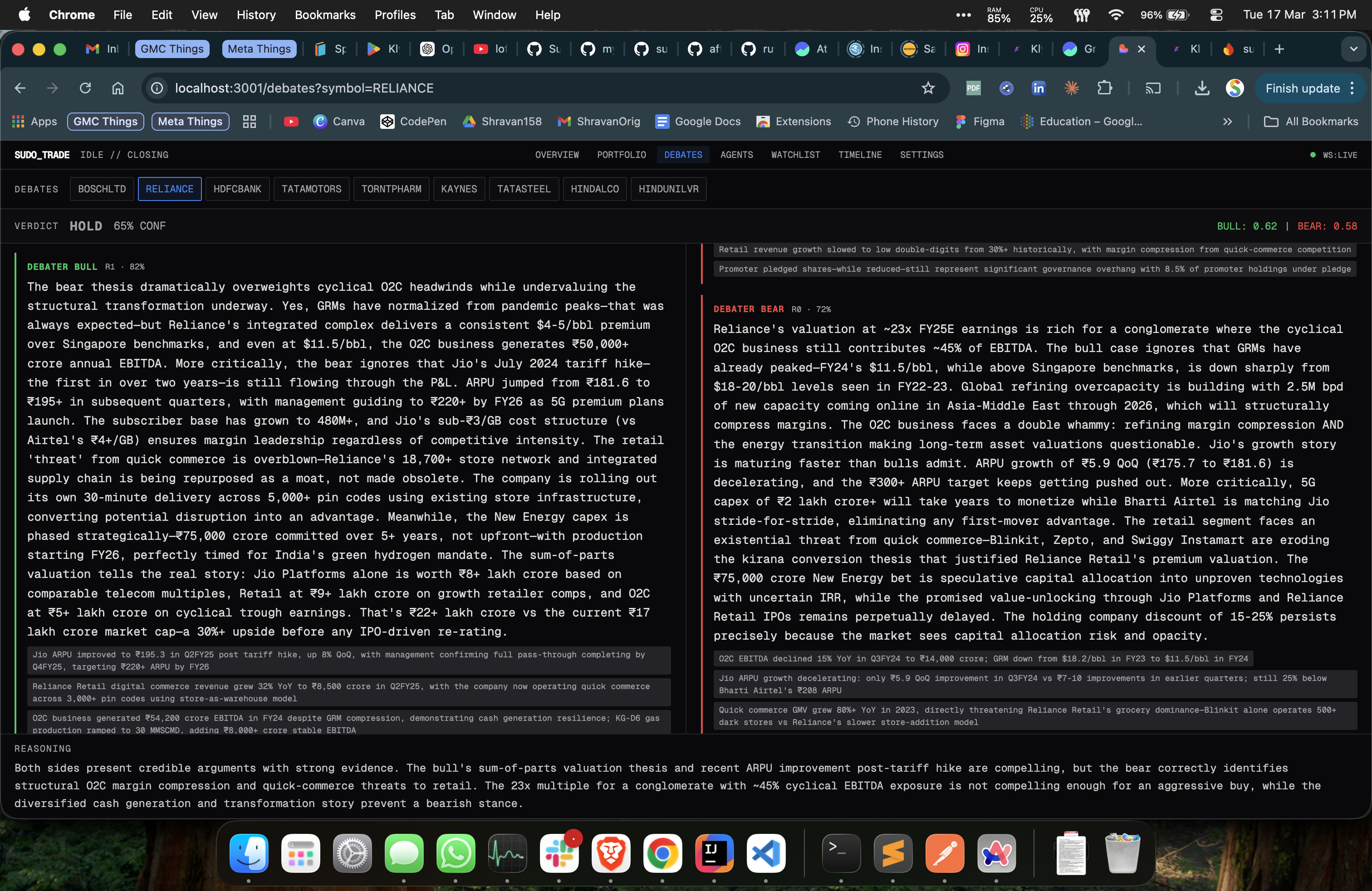
The Debate Mechanism
This is the part I'm most proud of. When the screener picks a stock, it doesn't go straight to execution. Pulls all the news and starts finding the co-relation. (This is where LLMs are good at)
Two separate agents argue the case:
BULL_SYSTEM = "You are a senior buy-side analyst who is BULLISH on the stock.
Build the strongest possible case for BUYING this stock.
Be specific - cite numbers, patterns, and catalysts. No vague optimism."
BEAR_SYSTEM = "You are a senior risk analyst who is BEARISH on the stock.
Build the strongest possible case AGAINST buying this stock.
Be specific - cite numbers, patterns, and warnings. No vague pessimism."
Two rounds. Bull argues, bear tears it apart, bull rebuts, bear rebuts. Then a third agent - a neutral "portfolio manager" - reads both sides and renders a verdict: strong_buy, buy, hold, sell, or strong_sell.
"No vague optimism" is doing the heavy lifting here. Force specificity and the arguments get genuinely good. The bull can't just say "strong fundamentals" - it cites the actual USFDA clearance and 150+ ANDA pipeline. The bear names the FDA warning letters and US pricing erosion at 8-12%.
The debaters also have memory. They remember past debates on the same stock - what they argued, what the verdict was, whether they won. A bull agent that got overruled last time on RELIANCE comes back with sharper evidence the next round. They learn.
I've shown this to people who run trading desks and brokerages. They get it immediately.
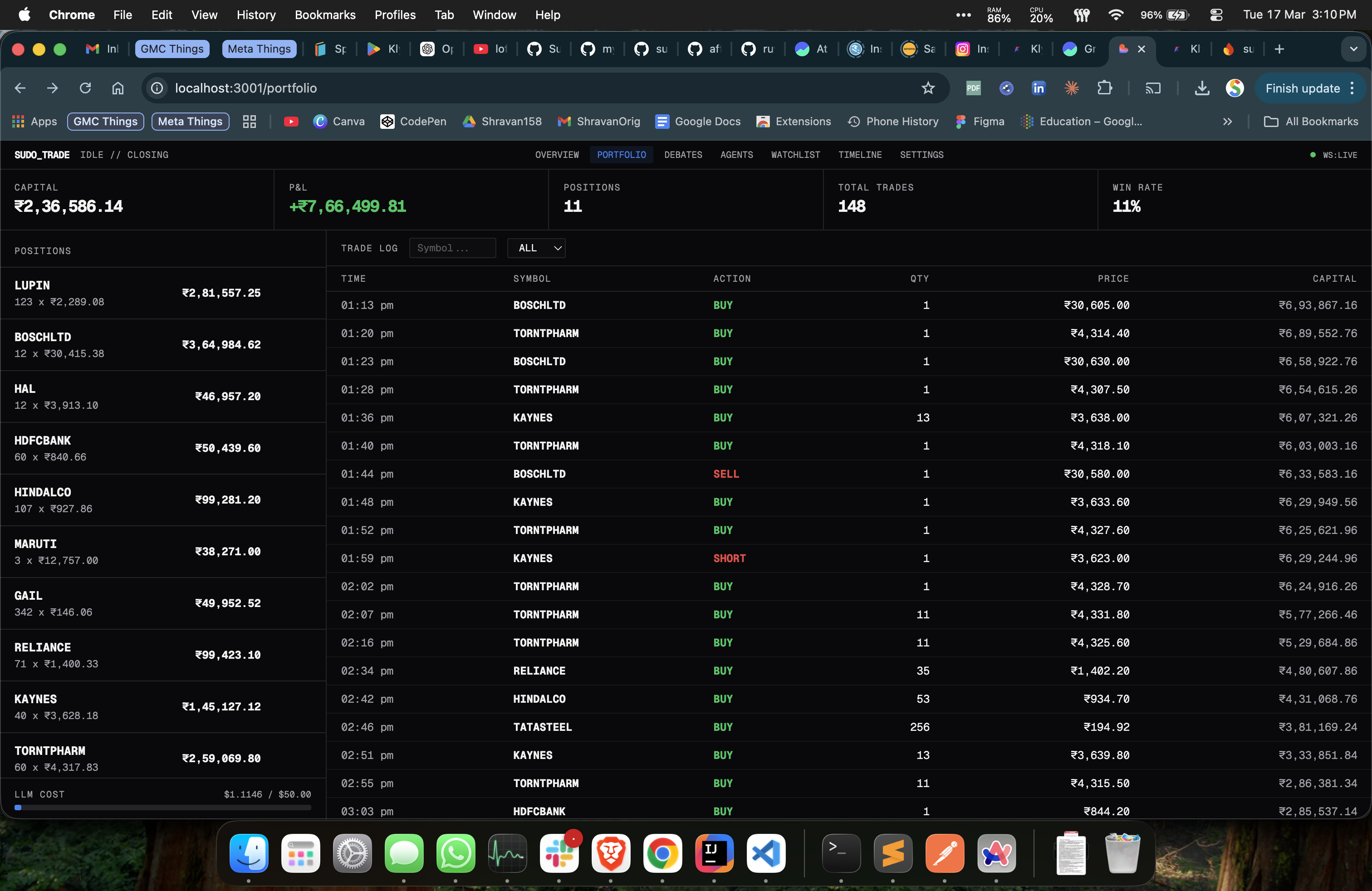
₹10 Lakh → ₹23.66 Lakh in 10 Days
I seeded the system with ₹10 lakh and let it run.
First few days were rough. The consensus engine was too conservative - every verdict came back "hold" at 65% confidence. The system debated 15 stocks and bought zero of them. An AI that never trades is an expensive screensaver. I tuned the prompts to bias toward action and added portfolio context so the master actually knew what it was holding before deciding what to do.
Then things got interesting. March 2026 - India-Pakistan tensions escalating, markets swinging 2-3% intraday. The kind of environment where retail traders panic sell at the bottom and FOMO buy at the top. The system ran through 10 days of this. ₹10,00,000 → ₹23,66,000+. 148 trades, mostly in LUPIN, POLYCAB, MPHASIS, and a handful of others the screener kept surfacing.
These are simulated fills - no slippage, no real liquidity - so take the exact numbers with a grain of salt. But the debate mechanism proved its thesis exactly when I hoped it would: during panic selling, the system was forced to argue both sides before committing capital. The bear agent kept catching overreactions the bull was ignoring. During relief rallies, the bull had to convince a skeptical bear before adding positions. Forced deliberation in a panicking market. That's the whole point.
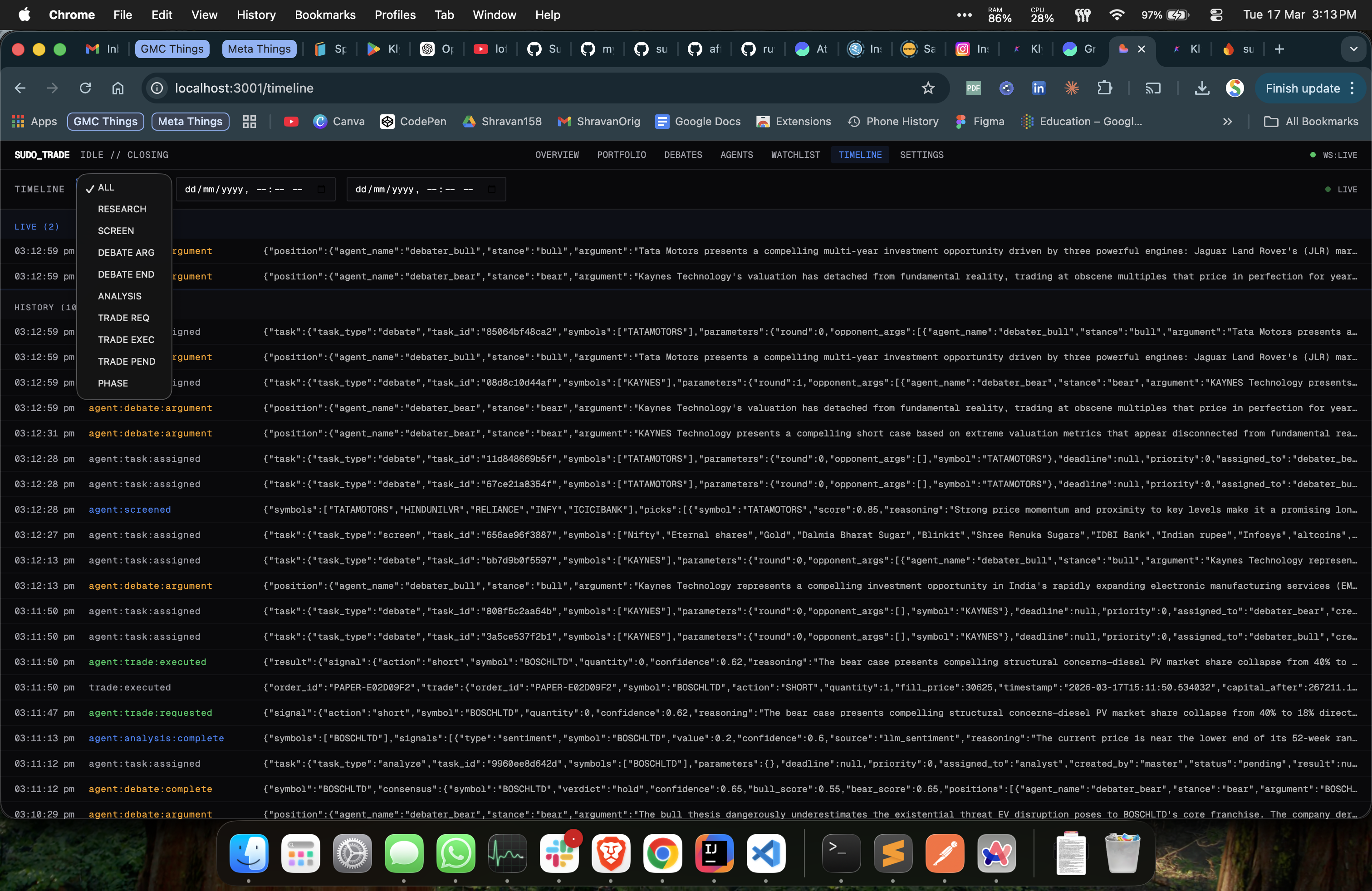
A Typical Day
The system follows NSE market hours and runs a six-phase schedule:
9:00 AM - ResearchAgent wakes up, scans RSS feeds from MoneyControl and Economic Times, points Claude at raw headlines and says "figure out what matters." It extracts affected symbols, whether the impact is bullish or bearish, significance, time horizon.
9:15 AM - ScreenerAgent pulls live quotes for 120+ stocks, sorts by momentum and volume spikes, then asks an LLM to rank the top 5 intraday candidates. Two-stage filter: quantitative first (free), LLM ranking second (costs tokens but catches things numbers miss).
9:15–2:00 PM - Debates run for the top picks. Bull and bear argue simultaneously in round one, rebut each other in round two. Consensus judge scores. If confidence > 60%, the AnalysisAgent runs sentiment analysis. MasterAgent makes the final call with full context: debate verdict, signals, capital, and current positions.
2:00 PM - Closing phase. No new positions. Square off intraday.
3:30 PM - Daily report. Cost per agent, decisions made, P&L summary, saved to Firestore.
The scheduler knows IST. Knows Republic Day, Holi, Eid, Diwali - every NSE holiday hardcoded. Skips weekends. And there's a force_active mode for when you're debugging at 2 AM on a Saturday and can't wait for Monday.
What It Actually Costs
Real numbers from March 19, 2026:
| Agent | Calls | Tokens | Cost |
|---|---|---|---|
| Debaters (bull + bear) | 127 | 213K | $0.65 |
| Master (188 decisions) | 34 | 83K | $0.19 |
| Researcher | 10 | 46K | $0.03 |
| Executor | 15 | 14K | $0.006 |
| Screener | 14 | 15K | $0.001 |
| Total | 200 | 370K | $0.87 |
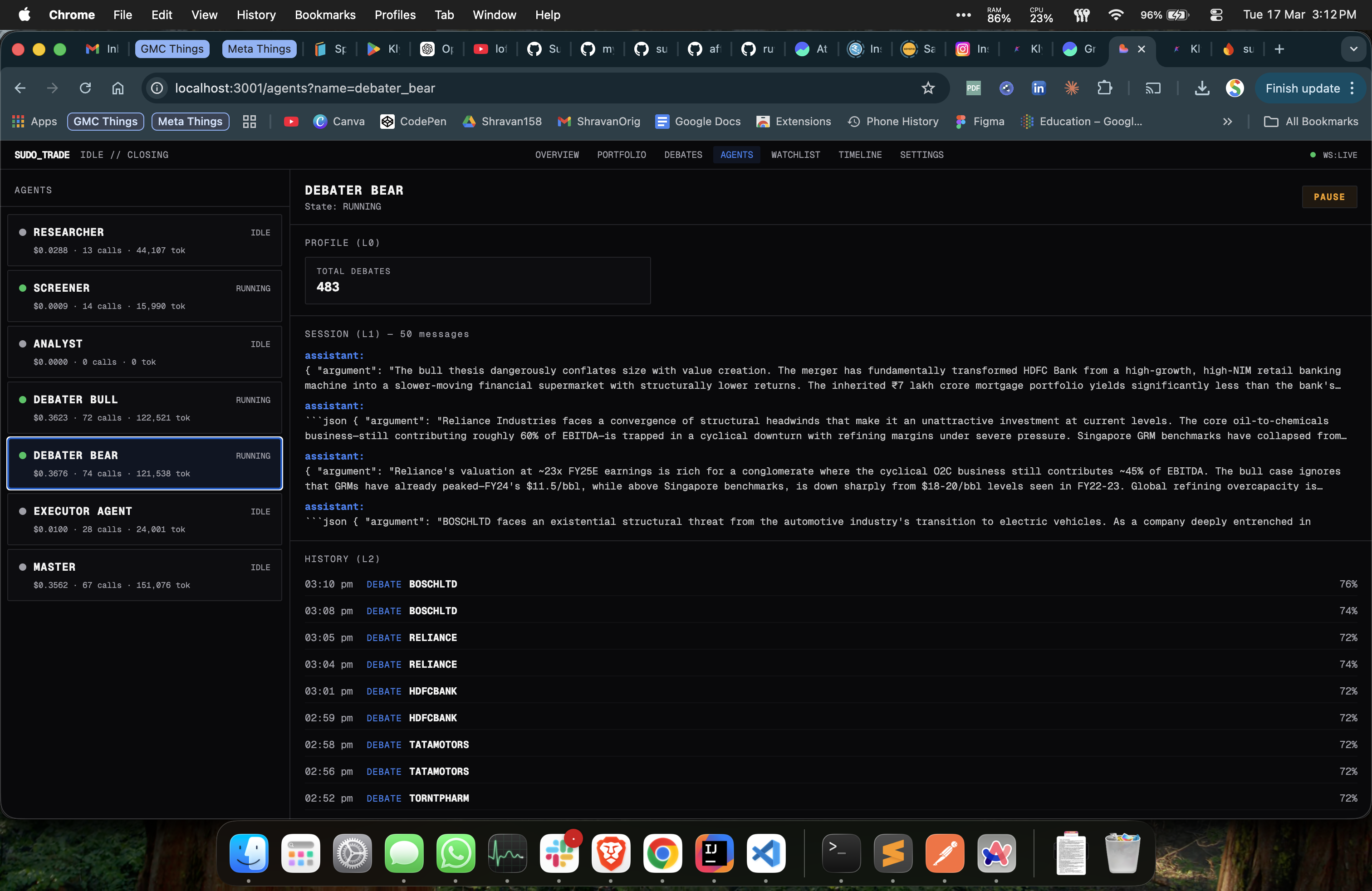
Per-agent budgets auto-gate - if debaters blow their allocation, they stop arguing and the master falls back to heuristics. \(50/day limit, never hit \)2. Different agents run on different models: Claude Opus for debates and final decisions, cheap models for research and screening. Different API keys, different endpoints, different providers per agent. Zero code changes to swap any of them.
The Architecture (Short Version)
Everything is a plugin. Components never import each other - they talk through an async EventBus:
engine.add("broker", GrowwBroker(role=BrokerRole.DATA))
engine.add("executor", PaperExecutor(initial_capital=500_000))
# Screener doesn't know MasterAgent exists
await events.emit("agent:screened", symbols=["POLYCAB", "INFY"])
# Master listens, doesn't know who screened
events.on("agent:screened", self._on_screened)
Swap Groww for Zerodha, Claude for GPT, paper for live - nothing else changes. Brokers have roles: one for market data, another for execution. Agents don't know which broker does what. They ask for data, they ask for execution, routing is automatic. Full architecture in the README if you want to go deeper.
What I Learned
The consensus engine was way too conservative out of the box. Every verdict came back as "hold" at 65% confidence for days. An AI that never trades is an expensive screensaver. I tuned the system prompts to bias toward action and injected portfolio context so it actually knew what it was holding before deciding what to do with it.
LLM temperature matters more than model choice. Debaters at 0.7 produce genuinely different arguments each round. Consensus judge at 0.3 stays analytical. Master at 0.3 doesn't panic. Get the temperatures wrong and you get either boring debates where both agents repeat the same points, or a system that changes its mind every tick. The temperature spread is the personality of the system.
What's Next
Live execution is one place_order() away - the protocol, the broker integration, the approval queue, all built. Kite Connect for real fills. Technical analysis as a second analyzer alongside sentiment. A proper backtest of debate-driven decisions vs simple momentum to prove that arguing actually makes money.
The engine repo is private. The dashboard is public - that's the part you can see. The brain stays behind the curtain.
Open for feedback and I can provide exclusive access if anyone is curious to contribut to the engine which is basiclly the brain of this system.
My devfolio: shravanrevanna.me - checkout more interesting and cool projects here.

